Cluster analysis is the process of quantitatively grouping data in such a way that observations in the same group are more similar to each other than to those in other groups. This image should clear it up.
Whenever you do a cluster analysis, you do it on a specific set of variables: for example, I could cluster a set of customers against the two variables of satisfaction and brand loyalty. In that analysis, I might identify four clusters: (loyalty:high, satisfaction:low), (loyalty:low, satisfaction:low), (loyalty:high, satisfaction:high), and (loyalty:low, satisfaction:high). I might then label these four clusters to identify their characteristics for easy reference: “supporters”, “alienated”, “fans” and “roamers”, respectively.
What does that have to do with language?
Let’s take a word, “human”. If I define “human” as “featherless biped”, I’m effectively doing three things. One, I’m clustering an n-dimensional “reality-space”, which contains all the things in the universe graphed according to their properties, against the two variables ‘feathered’ and ‘bipedal’. Two, I’m pointing to the cluster of things which are (feathered:false, bipedal:true). Three, I’m labeling that cluster “human”.
This, the Aristotelian definition of “human”, isn’t very specific. It’s only clustering reality-space on two variables, so it ends up including some things that shouldn’t actually belong in the cluster, like apes and plucked chickens. Still, it’s good enough for most practical purposes, and assuming there aren’t any apes or plucked chickens around, it’ll help you to identify humans as separate from other things, like houses, vases, sandwiches, cats, colors, and mathematical theorems.
If we wanted to be more specific with our “human” definition, we could add a few more dimensions to our cluster analysis—add a few more attributes to our definition—and remove those outliers. For example, we might define “human” as “featherless bipedal mammals with red blood and 23 pairs of chromosomes, who reproduce sexually and use syntactical combinatorial language”. Now, we’re clustering reality-space against seven dimensions, instead of just two, and we get a more accurate analysis.
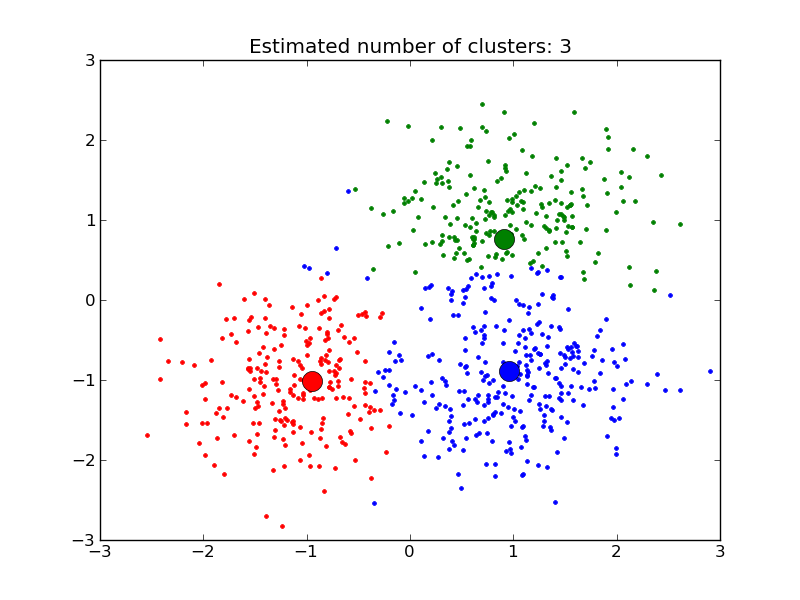
Despite this, we really can’t create a complete list of all the things that most real categories have in common. Our generalizations are leaky in some way, around the edges: our analyses aren’t perfect. (This is absolutely the case with every other cluster analysis, too.) There are always observations at the edges that might be in any number of clusters. Take a look at the graph above in this post. Those blue points at the top left edge, should they really be blue, or red or green instead? Are there really three clusters, or would it be more useful to say there are two, or four, or seven?
We make these decisions when we define words, too. Deciding which cluster to place an observation happens all the time with colors: is it red or orange, blue or green? Splitting one cluster into many happens when we need to split a word in order to convey more specific meaning: for example, “person” trisects into “human”, “alien”, and “AI”. Maybe you could split the “person” cluster even further than that. On the other end, you combine two categories into one when sub-cluster distinctions don’t matter for a certain purpose. The base-level category “table” substitutes more specific terms like “dining table” and “kotatsu” when the specifics don’t matter.
You can do a cluster analysis objectively wrong. There is math, and if the math says you’re wrong, you’re wrong. If your WCSS is so high that you have a cluster that you can’t label more distinctly than “everything else”, or if it’s so low you’ve segregated your clusters beyond the point of usefulness, then you’ve done it wrong.
Many people think “you can define a word any way you like”, but this doesn’t make sense. Words are cluster analyses of reality-space, and if cluster analyses can be wrong, words can also be wrong.
This post is a summary of / is based on Eliezer Yudkowsky’s essay sequence, “A Human’s Guide to Words“.