This week, I rehashed all the basics of Python. Since I haven’t studied it at all in ten years, this was a very useful refresher. (Basically, it seems to me that Python is essentially Java structure with something like JavaScript syntax. This is a huge oversimplification, but hey, it’s an extremely high-level language that I’m using it in an object-oriented way for this purpose. There are demonstrable similarities.)
The course I’m currently using doesn’t go over Python in any great detail, so if you’d like to supplement the Python they teach you, or you’d like to add to your knowledge of the language (since this course teaches only a very limited scope of Python), I highly recommend Learn Python The Hard Way. Python was my first programming language ever, and this was the course I used. It gives you a solid grasp of not just Python but how programming works in general.
In addition to the general Python refresher, I learned about all the libraries that I’ll need to use it to do data science: namely, NumPy, Pandas, SciPy, StatsModels API, MatPlotLib, Seaborn, and SciKitLearn. In combination, these libraries add methods that can import data from a variety of sources including Excel spreadsheets, conveniently calculate and tabulate relevant statistical data, do a variety of regressions and cluster analyses, and display elegant and understandable graphs.
This week, I learned how to do a simple linear regression (least squares). Next week, I’ll learn how to do multiple regressions and cluster analyses! And after that, the real fun begins with deep learning and AI. I’m looking forward to it!
In the future, expect me to start creating some little projects. I can’t do much with what I’ve learned this week, but by next week, I’ll absolutely have something at least moderately interesting, and I’ll absolutely do a nice write-up for it.
Japanese writing is a little bit intimidating. Even if we don’t consider kanji, there are two other writing systems to worry about, each with around fifty letters each. While these systems are phonetic (letters correspond directly to sounds), that’s still a hundred letters! (Well, 92.) How do you memorize them all?
When I first started learning Japanese, this was the bane of my existence. I knew I couldn’t do anything if I didn’t learn the alphabet, but unlike the Greek alphabet (which I’d learned before), Japanese “kana” come in blocks of two sounds, a consonant and a vowel. Further, though this is nice for reading comprehension after you already know the kana, the set of kana that begin or end with the same sound don’t similar at all (sa looks like this さ, se looks like this せ, and so looks like this そ). I had a huge problem learning nearly a hundred completely unrelated characters that had no direct connection to the individual phonemes.
One of the things that I tried when I was first getting started with learning the alphabets was cutting a hundred index cards in half and put a letter on each. Yet, a hundred Japanese-letter-to-romaji-translation cards later, I hadn’t really learned anything, and reviewing those cards just frustrated me.
It turns out, though, that the answer was incredibly simple, if perhaps slightly daunting. Here it is. Read. Even if you can’t understand anything. Read the Japanese version of the “this plastic bag is a choking hazard” warning on some packaging. Don’t worry about the kanji, just read the kana. Randomly use Japanese Wikipedia (fyi, the Japanese word for Japanese is 日本語, in case you’re wondering which language option to choose). When you look up kanji, look them up using a dictionary like Rikai, which gives you the pronunciation using kana. The optimal way to memorize anything is to use it.
When you first start, keep a kana chart (like the one at the beginning of this article) on hand and reference it for kana you don’t know yet. After a while, you’ll naturally be able to put the chart away and just read stuff. Even after you’re competent enough to not need the chart, keep reading: you’ll become so fluent with the kana that it will be easier to read them than to read romaji. (I have!)
I think the reason for this was that when I reviewed flashcards, every letter I didn’t know was a failure. However, when learning by reading, every letter I did know was a success. For me at least, it was a mindset shift. (Note: of necessity, I write from my own experience, and in my experience, reading works better than flashcards. However, if you do learn well with flashcards, I recommend using them… in addition to reading. You’ll want to eventually be able to read fluently anyways, right?)
All of that being said, here’s the most surefire way to make sure you don’t memorize kana: don’t use them. Learn Japanese using romaji. (Not only will this mess up your ability to learn kana, it will mess up your pronunciation.) Focus on grammar and vocabulary before learning the alphabet. Never be able to read real Japanese. There are many methods of learning Japanese, but I can inform you that this is the worst one.
Learning three alphabets can be pretty intimidating, but with a bit of time and dedication, and a lot of making sure you don’t beat yourself up when you don’t know stuff, you can get there.
Got a big baking spree coming up? Be it a Christmas dinner, a local bake sale, or anything else, if you need to do a lot of baking in a short amount of time, this post will tell you how to do it. Even if you have a more moderate amount of baking to do, following these tips will make the entire process that much more effortless, so you can make perfect, delicious cookies every single time.
Here are my baking credentials. First, I worked in a restaurant for three years, and during that time, I baked more pies, cakes, and cookies than most people will probably ever bake in their lives. Furthermore, every year, my family bakes an absolutely absurd number of cookies for Christmas. I’m taking 12+ batches, each of which makes multiple dozen cookies. We give bags of assorted cookies to coaches, teachers, and instructors of all varieties, then have enough left over to feed our household of seven for over a week.
To start you off, here’s your minimally adequate amount of equipment for any industrial baking spree. You can always have more than this, but here’s what you need to get started.
Electric mixer
Two sets of beaters for it, optionally also a whisk but you can whisk almost anything except meringue by hand without much difficulty
Four cookie sheets: at any given time, there should be two in the oven and two out of the oven being prepped with more cookies
At least two of each measuring implement (cups, spoons, etc.)
Sifter
Large bowls, a few of which are microwaveable
Other miscellaneous kitchen necessities: plastic and rubber spatulas, wooden spoons, oven mitts, cookie sheets, etc etc.
For any large baking spree, preparation is of the utmost importance. You need to make sure you have enough of all the ingredients, preferably on only one grocery store run. In order to do this preparation efficiently, run through every recipe you’re making (being sure to double, triple, quadruple, etc. the recipe as you’re planning on making it), note down every ingredient in its correct amount, and create a comprehensive tally. Then, take that list and check it against what you have in your house. Making conservative estimates, subtract the amount you have from the amount you need, and note down the delta. Create a shopping list from all those deltas for the ingredients, then shop from that list.
Great! You’ve prepared your ingredients, now prepare yourself.
First, make sure you have the right attire. You’ll want a short-sleeved shirt, a decently sized apron, and close-toed shoes. Here’s why, in order. You don’t want batter on your sleeves and you don’t want sleeves in your batter. Flour always makes a gigantic mess and there’s nothing you can do about that, also, it’s more convenient to have a place to dust off your hands. You will absolutely spill something or other on the floor and you don’t want to have the impulse to wipe off your feet, thus dirtying your hands.
After you’re wearing the right stuff and you’ve washed your hands, consider putting on some kitchen gloves. If you’re making multiple hands-on recipes (that’s any recipe that requires you mould dough with your hands), it’s way easier to change pairs of gloves than to wash your hands thoroughly.
Finally, set out all the ingredients for your first recipe. Organize primarily by the order the ingredients are used in the recipe and by what tools are required to complete that portion of the recipe. For example, all the ingredients which need to be sifted together should sit together next to the sifter itself; all the ingredients which need to be directly mixed together using the electric mixer should sit next to the mixer and the outlet it plugs into, and all the ingredients for the icing should sit off to the side with the piping bags.
I’m not being so anal about all of this for no reason. You’re going to run out of both time and counter space really fast, so it’s important to be hyper-efficient with both while you still have the mental bandwidth.
We’re ready to start baking now! Here are a few tips for preparing your recipe, before it goes in the oven.
When I worked as a prep cook in a restaurant, I had a tiny room—about the size of a home kitchen—to prepare nearly every dish that went through the restaurant. This is what I had. A counter along two walls with a sink and a gigantic electric mixer, a shelf containing dishes and measuring implements, and two 1.5*2.5 foot tables. I got really good at space efficiency. The biggest thing I learned, in addition to what I said earlier about grouping ingredients together, was that no matter how many recipes you have going at the same time, whether it’s one or ten, organization matters. If you’re not using an ingredient, put it away. I don’t care if you’re getting it right back out in an hour for your next set of recipes. Put it away.
Make sure you follow the recipe exactly. If it says to put the eggs in one at a time and mix well after each addition, you had better do that. The recipe isn’t telling you to do it for no reason. Note that I’m not trying to say you can’t experiment yourself and change the recipe—actually, you should absolutely do that, because what works for everyone else might not work for you, and further, the person who made the recipe might have some kind of an agenda (the recipe for chocolate chip cookies that you find on bags of Nestle chocolate chips requires far more chocolate chips than you should justifiably put in, because that’s what they’re trying to sell you). I’m trying to say that your reason for changing the recipe should be something better than “eh, it can’t be that important”. I make the best chocolate chip cookies anyone I know has ever had and the only reason is because I follow the damn recipe.
To conserve measuring implements, measure out dry ingredients before wet ones. Measure baking soda before vanilla extract, flour before milk, etc. As a special rule, if you’re measuring molasses for your recipe (ex. if you’re making ginger snaps), swish a bit of vegetable oil around in the cup measure before you put the molasses in. It will make the molasses stick to the cup measure less.
Here’s my final prep tip: take a sizable swath of counter space and lay out some parchment paper. If you’re like most normal people, you have nowhere near enough counter space for even a few dozen cookies on cookie sheets. Further, you probably don’t have enough available cookie sheets for that. However, if you snug the cookies up next to each other once they’re cool enough to scoop off the cookie sheet, you can fit a ton more in the same amount of space, and you don’t use up your cookie sheets.
While the first batch of cookies are in the oven, prep the next two sheets. I promise, the bake time is long enough for you to be able to do this. I’ve made two sheets of cookies in less than six minutes before. See, nobody cares what the cookies look like so long as they’re tasty, so you can be fast. Your literal only constraint is to make sure all the cookies in the oven at any given time are roughly uniform in size.
When you take a batch out of the oven, cool them on the racks for only a few minutes, then scoop them off and stick em on that parchment paper you laid out earlier. They’ll cool the rest of the way there, and you’ll have the trays freed back up to put more cookies on.
The baking is always the hectic part, since the perpetual cycle of bake-cool-transfer-prepare takes up every available moment. If you’ve done the previous organizational and preparation steps correctly, though, you can minimize the hecticness.
That’s it! My comprehensive list of steps for industrial baking. May your endeavors be successful, and your cookies be sweet. Good luck!
(Professional Development Project. Week 1: first update.)
Over the past year, as I finished up my AS in Computer Science, as I’ve been a participant in the Praxis program, I spent a good deal of time gaining entry-level skills in a variety of technological areas: SQL, systems analysis, web development skills including HTML, CSS, and JavaScript, etc. After all that, I wanted to pick something to focus on for continuing professional development.
As I considered what I should do next, I realized that while I have some decent skills in web development, I have a stronger aptitude in analytical areas. Further, I really enjoy solving problems and doing analyses, so I decided that I would go ahead and start doing that.
So far, I’ve completed about 130 out of 470 total segments (each includes a lecture and an accompanying quiz). This was basically the first two major sections: an overview including definitions of industry jargon, and an in-depth section on descriptive and inferential statistics. Given that I just finished a class in statistics as one of the final classes for my degree, I was able to skim through the second section.
Besides the refresher on statistics, what I basically learned this week was a lot of jargon and technical terms. I learned the distinctions between analysis and analytics; between business analysis, systems analysis, and data analysis; between neural networks and deep learning.
From here on out, you can expect weekly updates every Sunday, detailing what I’ve done that week. When it becomes applicable, I’ll be doing some coding projects as demonstrations of what I’ve learned by that point. I’ll post those here too, giving each project its own write-up, and I’ll then link back to those project posts at the end of each week in the wrap-up post.
At last, another art post. I was listening to some data analysis lectures to add data science to my repertoire, and since I need something to do with my hands when I listen to audio, I doodled this.
Since motivation unfortunately never comes pre-packaged with inspiration, I needed some of the latter. In my search, I came upon this excellent prompt site. If you so happen to be an advanced artist looking for inspiration, this may be for you. I selected an “elaborate” prompt; these seem to give you not only ideas about subject and/or situation, but also hints about color schemes and/or art style. I’ve never seen something so cool (or useful!) from an art prompt generator before. Anyways, the prompt I was given went something like this: “Reflect the emotion of rolling thunder in the distance. Use a Renaissance art style.”
Well, for the emotion, I’m honestly not sure how I went from “distant rolling thunder” to “rooftop swimming pool at dawn”, but heck, they convey the same emotion to me, anyway.
For the art style, though, I’ve never tried to do anything “Renaissance” before. My standard art style is vaguely Impressionistic but mostly anime, so I was wondering what the hallmarks and techniques of Renaissance painting were. After I figured that out, I’d figure out how on earth I was going to do that using markers.
It seems to me that the end result was vaguely Impressionistic, mostly anime, and with a hint of Renaissance. Some of the hallmarks of Renaissance paintings are strong dark/light contrast and several layers of glazes to create fuzzy outlines around things. I tried pretty hard to use a consistent color scheme but to use contrast as much as possible. The subject is mostly light-colored, with the exception of his hair and eyes, which are dark. A strip of light, washed-out yellow contrasts the warm greys of the surrounding pool deck. The opaque glass in the railing contrasts with the dark rails. Then, those rails contrast with the bottom of the sky (light), which itself contrasts with the top of the sky (dark). Even the water, which might otherwise be uniformly colored, contains shades from pure white to prussian blue. (Note: I used no black in this piece, just very dark greys, blues, and browns. This is in keeping with the style of most classical painting.) Lastly, for the fuzzy outlines, I simply didn’t bother to outline each form in pen (technique for cartooning called “inking”). I allowed the marker colors to bleed lightly into each other.
The end result was a kind of post-modern realism with a charming conflict of light source. Enjoy.
Every year since I was very young, I’ve volunteered at the Schenley Park Learn-to-Skate program that my skating club runs. Even for the four years I wasn’t skating, if purely because the entire rest of my family did it.
Nearly every year, the program has had an experienced coach take on the role of program director. The program director’s job is to organize just about everything to do with the program, from creating name tags for students and coaches to tracking the finances to organizing everyone physically on the ice sheet during classes, and much more. Fortunately, just as in any business, the director delegates some of these responsibilities, but even so, it’s a very big job.
This year, almost by accident, I was the one to take it on.
My mother, who organizes how Schenley Park runs as a subsidiary of the Pittsburgh Figure Skating Club (our home club), couldn’t find anyone to be this year’s program director. Since she was swamped with other work, she managed only to delegate the marketing responsibilities. With two days until the first class, we were freaking out: we still didn’t have a program director, and fortunately for the club’s coffers but unfortunately for our sanity, our marketing person had done an astounding job, and we had literally twice our usual number of students signed up.
Faced with this situation—twice the standard signup numbers, no program director in sight, and two days to deadline—my siblings and I were all given a prompt order to get everything ready. At first, it seemed it might be working, but eventually, between the sheer amount of work, the stress of trying to coordinate multiple people as efficiently as possible, and other miscellaneous factors, it became apparent to me that this wasn’t working.
I evaluated the situation and decided the most reasonable plan would be for me to simply take everything over. I had the most experience with the system overall; and primarily because of my good handwriting, I was always the first choice for the largest task, namely, creating student name tags. Because of the color-coded system we used to group name tags by level, the process went something like this. First, large quantities of colored card-stock had to be precisely cut via guillotine and sorted. Then, the names of all hundred and twenty some-odd students had to be written with Sharpie onto the cards, and the cards had to be put into name badge holders. Finally, the cards had to be put into gallon plastic bags, sorted by level, and organized cohesively into large bins so that the volunteers could hand them out to the students on class day.
For two days, I did nearly nothing else. Not only did I do the name tags, but I also organized the student names and other information into a database, deposited all their checks, acquired cash for the concessions stand, and organized our volunteer instructors.
Honestly, I’m very happy with how it all turned out. Everything was ready for the first class, my siblings and my mom didn’t have to worry about it, the kids and instructors got organized well, and the rest of the year ran pretty smoothly. On the day of class, since I knew everything about how everything had been organized, I also became kind of the go-to for volunteers with questions.
After a few weeks of this, on the drive home from class, my mom asked me, “So, you kinda seem to be running Schenley this year. Do you want to be program director?”
I have never once made a New Year’s resolution. I have never decided to change something significant about my life, starting on January 1st.
That isn’t to say that I’ve never decided to change something significant about my life. I decided I was sick of being overweight and out of shape, and I started hitting the gym. But I did that in April. I decided that I wanted to learn how to speak Japanese. But I did that in September. I’ve resolved to do a lot of things, but I never hung around twiddling my thumbs until January to start actually doing them.
This seems, at least to me, to be the reasonable course of action. If something about your life needs changing, it makes sense to start changing it as soon as possible. If you decide you want to quit smoking, program in Python, speak Mandarin Chinese, lose thirty pounds… start right now, not at year’s end.
Now, perhaps people make resolutions on New Year’s because the start of a new year prompts people to look over their life and actually make the decision that they want to change their lives. This seems like a reasonable argument at first, but then you have to consider that the culture of making resolutions on New Year’s is really more a method of putting people under the gun and demanding that they find a Grand Way To Change™, rather than a way of sparking consideration or discussion on the possible ways one’s life could change direction.
Furthermore, a lot of people don’t even keep their New Year’s resolutions. Actually, a frankly huge number of people don’t keep them, to the extent that I frequently wonder whey people even bother setting them. (I read a statistic that around 8% of people keep their resolutions, which seems likely, but I can’t find the original research, so I won’t tout that as fact.)
What’s wrong with people? Why do we have a societal expectation where, once a year, people will set goals, then fail to follow through with them? Why do we harbor a culture of annual disappointment?
Part of the reason people don’t keep resolutions is that there is no actual change happening between December 31st and January 1st. They’re two days which are right next to each other, just like March 18th and March 19th. The only significance to that particular collection of days is the cultural expectation we’ve attached to them: that is, a new year should be a quantum shift of progress.
The cultural expectation of some kind of quantum shift, coupled with the fact that no such quantum shift actually happens, leads otherwise reasonable people to set incredibly unrealistic goals for no good reason. People who, if they made this kind of goal in mid-March, would say “I’m going to try and start hitting the gym once a week on Sunday afternoons”, suddenly go off on ridiculous moonshots like “I’m going to start hitting the gym every single day as soon as I get home from work, and I’m also going to cut my carbs in half and become a vegan” as soon as December 31st rolls around.
As such, my best recommendation for how to set resolutions and then follow through on them is to not set them on New Year’s. Any other time of year will have much less pressure attached to it.
Actually, I amend that statement. It’s probably better not to set resolutions at all. Just decide that you want to improve in an area, and get started with the baby steps right away.
A big goal like “I want to become conversationally fluent in Mandarin Chinese”, even if you have a pretty good idea what ‘conversationally fluent’ means, can be incredibly daunting. That kind of thing will absolutely take you years, maybe decades, and looking at the whole thing at once can just make you want to quit outright. On the other hand, googling “beginner Chinese lessons” and watching a handful of funny animated Youtube videos on the subject is easy.
These kinds of “resolutions”—goals with no particular time limit that you’re setting purely for self-improvement—should theoretically be the easiest kinds of goals you set. Whereas in the work world, you have specific deadlines and deliverables, you don’t have any of those in your personal life. You don’t need to learn Chinese in five years. Maybe you want to, but that’s not actually the same thing. Personally, I’d like to learn Japanese in less than a decade. But I’m not going to be fired from my job if I don’t achieve that goal on schedule.
A resolution should be a matter of fun, personal self-improvement, not of disappointing annual self-loathing. So, even and especially if you’re not reading this on New Year’s – what’s your new resolution?
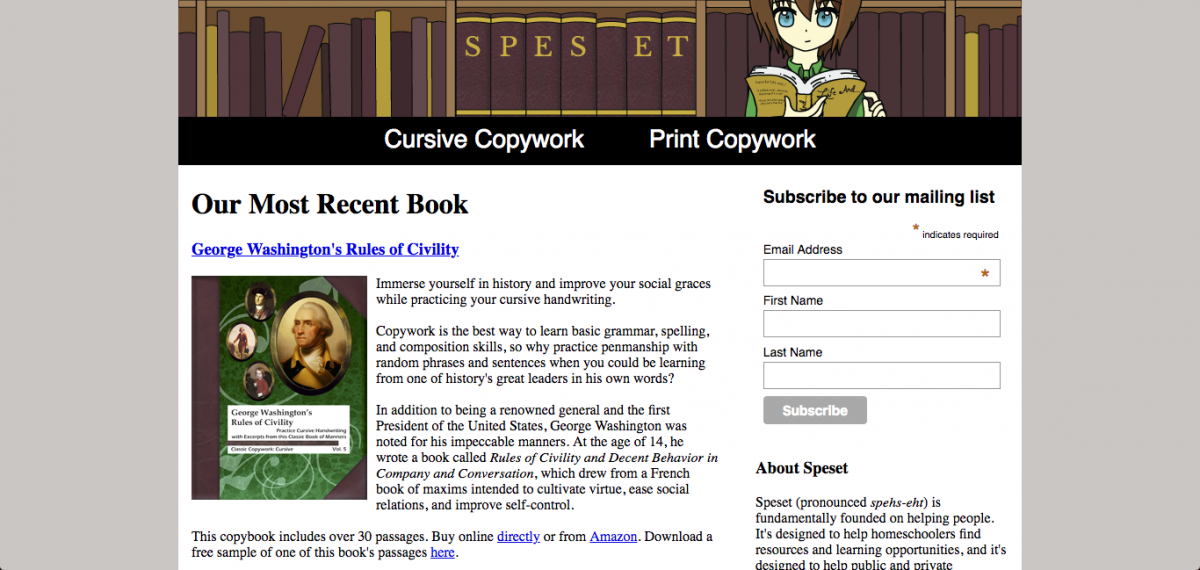
You know that thing you used to do as a kid in elementary school, where you learned handwriting by copying boring phrases and sentences over and over? That has a name. “Copywork.” And several years ago, my mother decided she wanted to make it interesting. How? Instead of those boring phrases and sentences, she would create copywork books with quotes from great fiction, literature, and even U.S. presidents.
Here’s the story of how I helped make that into a company.
Growing up homeschooled as the kid of an entrepreneur, I ended up using a lot of resources that were created by my mother. I took whole classes that my mom made up, start-to-finish. (These, of course, were in her areas of expertise.) One of these resources that she created early in my homeschooling life was copywork books.
If I hadn’t stood in awe behind her red patchwork recliner as she typed up a line in one of them, I would never have known that she created the books. They were professionally formatted and bound—my dad is a graphic designer, so I imagine he did that part— and there was even one of those little promotional blurbs on the back.
As we all gradually grew out of needing copywork books, she moved on to selling them to other homeschooling parents in our area. And then, one morning when I was around fifteen, she sat me down in the living room.
She talked to me about the fact that she wanted to make this into a real business, which would be able to sell not only her copywork books but also other homeschooling resources that she might come up with in the future. In order to do that, she would need two things: an online presence, and a name. Evidently, she wanted my help with those.
Having only recently started web programming, I decided to tackle the easier thing first, and I started brainstorming names. After a few minutes, I came up with the Latin half-sentence “spes et”, which means “life and”. I figured that leaving the part after “and” blank would let the reader fill in whatever they wanted. My mother and I contracted the phrase into one word, and at last, Speset was born.
Once I had a name, I got started on the graphic design. I sketched out on paper the general idea for what I wanted to do—a young person standing in front of a bookshelf with “S P E S E T” spelled out on book spines—then imported the image to Adobe Illustrator to create the real vector. I made sure that the image was a web-worthy 960px wide and used the “save for web” function in Illustrator (back when that was a thing, it’s called “export for screens” now) to make sure that everything rasterized nicely.
One of the biggest problems I had when creating the graphics for Speset was the color scheme. My dad’s aesthetic is dark wood and leather, so he created the book covers with that in mind. Unlike a book cover, though, a website looks kind of ugly with a leather texture, so I had to find a way to convey the same idea with only flat colors. I ended up settling on a bright gold, a dark red-purple, and a light reddish-brown. I thought I might add a wood-grain texture to the background of the site, but I decided it would be too distracting and opted for a simple warm grey instead.
After the graphics were finished, I had to get started on actually coding the website. To start with, though at this point I knew almost no PHP, I used the .php file type because there was one thing I’ve always loved to do in PHP: includes. Though I knew how to import an external stylesheet or script, I didn’t know it was possible to import another HTML file. Because I wasn’t a fan of copy-pasting code over and over, or of accidentally failing to copy a closing div tag and thereby ruining everything, I loved to use PHP includes. I still do; though I now know that HTML can do includes, and though HTML5 can do forms now (I used to need PHP for that), PHP is still more powerful than HTML, so I use it to keep my doors open.
I put my nice header image into an include, made other includes for the nav bar and footer, then went about writing content. I already had the blurbs I wanted to include—they were the same ones on the backs of the books—but I needed to figure out how to format them. Given the very small amount I knew about CSS at the time, creating a two-columned list next to an image that used a specified font size and amount of space between columns was a daunting task!
After a lot of fiddling and finnicking, I’d added all our books, the final thing I needed to do was add the mailing list from Mailchimp. The code wasn’t the hard part, since they provided the form and I just had to style it; setting up the account in the first place was a little more challenging. I eventually managed, though, and I set it up to send me emails whenever I gained subscribers to the mailing list.
Over the course of the next few years, I made a handful of improvements to the website, but mostly just added new books as they were published. One thing happened that I wasn’t expecting, though. I didn’t figure it out until earlier this year, when I started cleaning out my inbox, but when I did, I realized I had a lot of emails from Mailchimp.
At that time, I hadn’t sent out a single email to any of the Speset subscribers. I hadn’t even done a single ounce of marketing. Beyond the mere existence of the website, I had done nothing at all. And yet, I kept seeing emails from Mailchimp. After a few scores of them I thought to log in to my account and check the subscriber statistics. I blinked a few times when I saw the number. Over a hundred?! Dude!!
I’ve since realized the probable reason this happened. Before I’d created the website, the books already had a niche following on homeschooling forums: my mom had done a good job at word-of-mouth marketing. But, they were all just floating about in the Amazon aether, without anything connecting any of the books to each other. Once they all had a single home, the people who’d already cared about them were able to get to them more easily, and to recommend our products more easily. The mere existence of the website promoted both brand loyalty and word-of-mouth.
I decided to make カツ丼 (katsudon) for New Year’s this year. It’s definitely the most complicated thing I’ve ever made for New Year’s—our family’s usual dinner is fried chicken and New Year’s pretzel—but I really wanted to make it for everyone and I hadn’t thought of it in time for Chanukah and I was too busy making cookies during Christmas.
It was a wild goose chase of strange Asian markets to try and find the ingredients. I found a surprising number of them in my local grocery store—who knew Giant Eagle carried mirin?—but at the end of my day of shopping, during which I had asked かつおぶしはどこですか (katsuoboshi was the thing I was looking for: it’s dried tuna flakes) more times than I can count, I ended up in a strange little Oriental market in a tiny strip mall that shared a parking lot with a Red Lobster.
My siblings, who made the mistake of deciding to come along, petered around the market, whispering to each other because speaking English in the market felt a little bit like infringing on the delicate island of Asian culture within the massive sea of English-speaking America. When I muttered to myself, I very deliberately did so in Japanese, for the same reason. It felt like a heinous act of cultural appropriation to so much as exist in that store, and even more so to speak in a non-Asian language.
I failed to find what I was looking for, so I bought a poor substitute (dried scallops) and we went home. During the car ride, we talked about the way it felt to be Jews infringing on Asian culture. Then, as we walked into the house, I saw that my sister was carrying a bag with some brightly-colored packages in it. Knowing that she had a hard time even navigating the store since everything was in some combination of Chinese, Japanese, and Korean, I wondered what it was that she had picked up.
“What is that?” I asked, gesturing to the packages.
“Oh! This is a dessert dumpling thingy that we all had when we went to Hong Kong! Everyone loved it, and I saw it, so I picked up some!” She proceeded to rant enthusiastically about how good the thing was, and as soon as we got home, she took out one of the packages and made it right there and then. She was right. It was awesome.
After we ate our dessert dumpling thingies, which turned out to be called milk yolk buns, I started cooking my カツ丼. The first thing I did was boil the dried scallops to make a poor substitute for だし (tuna broth). Then, I went about making とんかつ. I heated the oil and set up everything I needed to bread the pork tenderloins, then breaded them as I watched the oil heat up in the pot. When the oil was hot enough that a panko crumb dropped into it would float right to the top, I started frying the breaded pork. At some point, my sister put on some 80s rock.
As we all cooked and ate and hung around, I remembered something. One of our first missteps on our wild goose chase for katsuoboshi was an Indian market. While searching up and down the aisles, one of my sisters asked for help from an older Indian man. He said that he’d never heard of what we were looking for, since the store didn’t even carry Japanese foods, but he was very happy that we were here, and he recommended trying some Indian food if we’d never had some. He even gave us a specific restaurant at which we should do so.
And that got me thinking. If I was walking around a Jewish market—I’ve never been to one, since Giant Eagle has a good Kosher section, but if I had—and somebody came around and clearly had no clue what they were doing, I would have been happy to help them out. Obviously, if they’re here, they have some interest in Jewish food: how awesome is that?! Somebody who isn’t a part of my culture wants to learn about it! I couldn’t imagine myself thinking of it as anything other than flattering.
On a regular basis, my family has goyish visitors over for the High Holidays. We love sharing our culture with people who aren’t a part of it. And as I thought about it, so did that Indian man who saw clearly non-Indian people trolling through an Indian market looking confused. So did the person who hosted my siblings when they stayed in Hong Kong, who taught them about the milk yolk buns. And so would I, if I had been in either of those positions.
Nowadays, we hear all about cultural appropriation. It’s a terrible, awful thing to do, they say. But what exactly is it? What counts? Because if I saw a goy wearing a yarmulke or making latkas, my first thought would be “wow, that’s neat!”
As a member of a minority culture myself, I’ve never understood why “cultural appropriation” is a separate concept from “ridicule” and “theft”. The times when it makes sense for people to shout “cultural appropriation” seem to fall into those two categories: either someone is imitating a kind of cultural stereotype that ridicules the culture in question, or else a corporation is stealing art made by a culture without paying the people who actually came up with the art in the first place.
If cultural appropriation is just ridicule and theft as they relate to culture, then obviously it’s bad, but ridicule and theft are already bad. Why have a separate word? And further, I’ve heard some people calling “cultural appropriation” when someone does something like show genuine interest in a culture, or want to combine parts of that culture with parts of their own. And, speaking again as a member of a minority culture… I appreciate the effort, but I think people are trying to protect me from something I really don’t need to be protected from.
When some other culture steals American majority culture, nobody complains. In Japan, people celebrate Christmas, but they do it in some notably Japanese ways. Notably, there is no “Christ” in Japanese Christmas: a very small fraction of Japanese people are Christian. Further, they have a specific Christmas cake; Christmas is time for couples, not families; and on Christmas Day, they eat KFC. Basically, Japanese people stole American Christmas and made it theirs. They committed the sin of cultural appropriation. Right?
Not really. Here’s the key difference, and it doesn’t have to do with minority vs majority cultures. The things that we call “cultural appropriation” that are genuinely despicable happen when someone steals a culture or cultural tradition and pretends that it’s theirs, that they own it. The sorts of things people call “cultural appropriation” that are actually fine happen when someone uses aspects of a culture or cultural tradition, but respects the origins of the culture and defers to the people who actually have that cultural background. They borrow, they don’t steal.
You don’t need a “get out of cultural appropriation free” card from a Real Member Of That Culture™ in order to be able to borrow culture. You can borrow whatever culture you want, so long as you do it respectfully. Understand that the Real Members Of The Culture are the keepers of their culture, if not the proprietary practitioners of it. And ask them questions, not permission.
We native Jews are the keepers of our culture. If you would like to borrow it, we would be flattered. Yes, you should learn about our culture before you try to imitate it, since otherwise you might accidentally imitate a stereotype. Yes, you shouldn’t mass market Jewish art without compensating the Jews who did the art. (Art theft is still art theft, and it’s still bad.) But none of that means you’re not allowed to have latkas for the Fourth of July if you like. In fact, they’ll fit in perfectly with all that deep-fried American goodness. (Please eat latkas. I love them and I’m sick of having to explain to people what they are.)
Here’s a passage from the Passover Haggadah. “All who are hungry, come and eat; all who are needy, come and make Passover.” Basically, if you want to come in and celebrate our holiday with us, we’d be happy to grab you a yarmulke and a place setting. I think if everyone had that kind of attitude towards culture, the would could be a better, more unified place.
I’ve been studying Japanese off and on (accommodating a busy schedule) for about two months. During that time, I’ve accumulated a number of Japanese-learning resources that work incredibly well for me. So, here’s a short list!
Tae Kim’s Grammar Guide.Tae Kim is my best source for grammar so far. He teaches Japanese grammar from a Japanese perspective instead of trying to translate English phrases into Japanese. This guide is easier for me to understand and use than Genki, and it’s got the only decent explanation of the は vs が distinction that I’ve ever read. He absolutely does not skimp on the kanji though, which can make for slow going through his lessons.
Remembering the Kanji. This book lets you learn kanji the same way that people come up with kanji in the first place: by using your imagination. It gives you a key word for each kanji, and introduces them all in an order that builds on itself. You’ll be introduced to simple kanji, then more complicated kanji that combine the simple ones together. RTK contains all 2200 common-use kanji as approved in 2010.
For reference on the usefulness of this method: as of the date this was posted, I have seen 200 of the 2200 kanji in the book. I remember every single one, despite a complete lack of any kind of spaced repetition system, or in fact any memorization method besides the book itself. I made a handful of flashcards and I review them on rare occasion just to make sure I still remember everything. I always do.
(Note: RTK book 1 does not teach you to read the kanji. That comes afterwards, in RTK book 2. I have not used this book, so I can’t recommend it. However, once I finish RTK 1, I’m absolutely planning on buying RTK 2.)
Rikai extension for Firefox/Chrome. For Firefox, it’s Rikai-chan. For Chrome, it’s Rikai-kun. They’re the same thing. Basically, Rikai is a dictionary. You can hover your mouse over a word, and it will pop up with the pronunciation (in hiragana) and definition(s). It’s really helpful for figuring out unknown kanji readings, for unknown words in general, that kind of thing. Be sure that you know the grammar, though: beyond telling you which form a verb is in, Rikai will not tell you anything about the grammar of the sentence, or even which words are which. You hover over the first kana in a word. If you hover over a kana that is not the first one in the word, you will get the wrong definition. Rikai is a dictionary, not a language god, so treat it as such.
HiNative.com. HiNative is a super useful website for asking specific questions about any language. Basically, you put in your native language and your language of interest, then you answer non-native speakers’ questions about your native language while native speakers of your language of interest answer your questions about their language. My current questions-to-answers ratio is 1:50, but yours can be lower than that. Just to be courteous, try to make it at least 1:1.
Italki. Everybody needs conversation practice, and this is italki’s specialty. On italki, there are a whole bunch of teachers for a whole bunch of languages, Japanese included. You can get a professional teacher, who has an actual degree or teaching certificate to teach the relevant language. Or, you can get a community tutor, who is a knowledgeable native speaker with whom you can converse. This is the single most expensive resource on this list (RTK is $20 on Amazon and everything else is free), because you pay per lesson. Still, it’s also one of the most important resources. Conversation is the single most important part of learning a living language.
Japanese Youtubers. I cannot stress the importance of just hearing Japanese spoken by actual humans who are not actors. Just like people in America don’t actually talk the way characters do in American dramas and cartoons, neither do Japanese people talk the way that characters do in Japanese dramas and anime. My favorite Youtube channel is Dogen. He makes a series called “Advanced Japanese Lessons”, which are basically just ultra-dry-humor comedy skits in Japanese about the oddities of Japanese culture. Dogenさん is not a native Japanese speaker, but his accent is so absolutely perfect that he might as well be. (Don’t take my word for it. This native speaker with a penchant for nitpicking Japanese nitpicked Dogen’s Japanese.) I also occasionally listen to Japanese vlogs.
Finally, the built-in Mac dictionary. If you happen to have a Mac, make use of this. Not just for a dictionary, but for pronunciation practice. If you’re not already aware, Japanese is not stressed like English. (In English, we say “chopstick”, with the first syllable said louder. In Japanese, however, they say はしwith the first syllable higher pitched. It’s the same syllable that’s accented, but in English we use stress, whereas in Japanese they use pitch. This is why the accentuation of Japanese words is called “pitch accent”.
That being said, the Mac dictionary has the ability to tell you which syllables in a word have what pitch. Here’s a Dogen video where he explains how to use the Mac dictionary to find the pitch accent of Japanese words. I’ve been using this for some time, and evidently my pitch accent is pretty good, because in my very first ever Japanese lesson on italki—literally the first time I ever spoke Japanese aloud to another human being—my sensei thought I was capable of having actual conversations.
There is one main thing that I do not have a good resource for. Vocabulary. In absence of the “perfect” resource, I’ve been using Duolingo Japanese. There are a number of things I don’t like about it (pretending that が indicates the subject, for example, or not teaching all the kanji readings systematically), but it’s good for now. However, I am still on the lookout for good resources for this, and whenever I find one, I’ll be sure to post it here.
Have any good resources that you’d like to talk about? Put them in the comments!